
With the increasing popularity of social media and content that is being uploaded or created has led to the raise in demand for better recommendation systems. Popular applications in the market each has its own strategy of recommendation system. Recently, I have read some articles on how Netflix implemented its recommendation system. Here are some insights into it. Let us dig deeper.
Netflix personalized recommender system is complex and has multiple models developed to cater each of the categories like “Top picks for you” or “similar videos”. As they extended this recommender system across multiple business needs, the architecture has become quite costly.
The implementation of recommender system has started back in 2006 where a Netflix prize was announced for movie rating prediction using machine learning. But later they moved to streaming service in 2008 which changed their focus. They adapted the personalization algorithm to this new scenario.
Personalization started in home page where each row has a group of videos and it has a title with intended meaningful connection between videos in that group. For example, top 10 row which includes all family members with different taste so it should be optimized for accuracy and diversity.
Other important element is awareness of why we have chosen that option with explanation like “3 friends watched this”. They also integrated with the Facebook which extracts connections and shows rows like Friend’s favorites. Other most recognizable personalization is collection of genre rows and having high level categories like comedies and dramas. Choosing the genre and subset of titles within each genre and ranking those titles. Next element if freshness. They also present the reason for choosing the video based on explicit feedback through taste preference or recent plays, ratings and other interactions. Similarity is the important source.
Ranking
In all of the above the ranking a choice of what to place the items in a row is critical for effective personalized experience. Ranking is decomposed into scoring, sorting and filtering set of movies to present.
The popularity of the video definitely makes it better ranked but to better personalize there should be even better algorithm. So it is important to produce ranking balancing the user preference and popularity. This gives us two dimensional linear approach between the features popularity and predicted rating. But how is the weights for each calculated? One approach can be done by selecting positive and negative examples from historical data of user and let ML algorithm learn the weights that optimize the goal. Along with these features when we add multiple other features and optimize the linear model with Support vector machines, Decision Tree. They have seen significant progress in the way prediction were made by 200%.
Data and Models
Now that you know what is the importance of data and models.
- The data was not a challenge as they have billion item ratings from members and receive millions of them everyday. Along with popularity they grouped the videos by regions and popular within a group.
- They also have metadata for each videos and multiple data collected from user interactions like scrolls, clicks and time spent on each page.
- They also added external features like box office performance and critic reviews, demographics, location, language etc.,
Coming to model, there are numerous models and also they found that supervised algorithm was giving better performance compared to clustering algorithms. But they tried optimizing and used the A/B testing or bucket testing as traditional means. They tested the new model with trusted members selecting some thousands combining offline and online testing process.

Once offline testing was validated the design was launched and tested online with few members and if there are satisfactory results move it to all the members
System Architecture
This architecture I would be discussing was published back in 2013 whcih has got multiple changes later. But it is always useful to understand from where it started. Here is the glimpse of it

The architecture performs computations offline, nearline and online.
- Online computation can respond better to recent events and user interactions and respond in real-time. This is subjected to SLA where user is waiting for recommendation to appear within the latency allowed. Also should have fallback mechanism in case of failure
- Offline computations has less limitations on data and computational complexity. but it can easily grow stale. SLAs are not important and new algorithms can be deployed. For rapid experimentation, they have taken Amazon EC2 and optimizing the algorithm was the main goal of engineering team
- Nearline is between these which compromise both modes and performs like online. but the results are not shown immediately on computation but store them. This computation is done in response to the user events.
- Model training that uses existing data to generate a model that can be used for actual computation. The approach like Matrix factorization are more natural fit for hybrid offline/online modeling.
Event and data processing
Much of computations can be done offline like model training and batch computation of intermediate or final results. although models are trained offline in batch mode, we also have some online learning techniques where incremental training is performed online. For batch computations, we need to work on large data so it is beneficial to use distributed fashion hence running on hadoop or hive jobs are ideal. For notifying the subscribers of the results, handling errors and monitoring or alerting, a tool called Hermes with publish-subscribe framework was used.
They use the term signal to refer to fresh information we input to algorithms which is obtained from live services. The events from the users like clicks, browsing, viewing or even the content of viewport is collected and aggregated. Events are small units of time-sensitive information that need to be processed with the least amount of latency. Data is more dense information units that might need to be processed and stored for later use. For having near real-time event flow it is managed using internal framework called Manhattan. This is the distributed computation system central to algorithmic architecture for recommendation. the data flow managed mostly through logging into chukwa to hadoop. Later sent to Hermes as publish-subscribe mechanism.
Recommendation results
These recommendation results can be serviced directly from lists that we have previously computed or they can be generated on the fly by online algorithms. The intermediate results are stored offline by using Cassandra, EVCache and MySQL. MySQL allows for structured relation data storage useful for querying. Cassandra is a well-known and standard solution when in need of a distributed and scalable no-SQL store. Sometimes where intensive and constant write operations are required they use EVCache.
Learning a Personalized Homepage
As the netflix has many videos to be displayed on a single page, each member comes with own set of interests, it is important to best tailor their homepage. The users can navigate horizontally in row of similar categories or vertically. We have to figure out how to choose rows to display on homepage.
By grouping the videos based on the series of rows it is easy for members to navigate through catalog. Natural way is to group by Genre or sub-genre. the relationship between videos need not be metadata relation alone, but it can also be formed from behavioral information.
Once these video groups are formed, it is being assembled for the home page based on the candidate grouping. Next, they filter each group to handle concerns like maturity rating or remove some previously watched videos. Then ranking is done to the videos such as most relevant videos for the member in a group are at the front of the row. From this set of row candidates then the row selection algorithm is applied to assemble the page. Once assembled, deduplication to remove repeated videos and format rows to the appropriate size for the device.
The recommendations considers the user perspective where allowing them to discover new videos and also find something they are watching. They focus on depth of the catalog based on interest and breadth across areas to explore new interests. It also considers the limitations of the device that the page is loaded.
Building page Algorithmically
The most basic approach is rule based approach where there are defined templates that dictates what types of rows can go in certain positions of the page. the only personalization was to select the candidates in the row. For this they have extensively used A/B testing to understand where to place rows for all members. But this approach has a drawback where the number of videos became larger the quality of videos and amount of diversity and affinity of members towards certain rows was ignored. Adding new row is also harder.
To overcome this, they have implemented row-ranking approach where we can leverage lot of existing recommendations or learning to rank approaches by developing scoring function for rows applying it to all the candidate rows independently, sorting by that function and then picking top ones to fill page. Even though the space of rows may be relatively big, this type of approach could be relatively fast and may result in reasonable accuracy.
Now to add diversity the row ranking approach can be switched to stage-wise approach using a scoring function that considers both a row as well as its relationship to both the previous rows and the previous videos already chosen for the page. We can go with greedy approach taking maximum score but that would not be optimal way for the diversity. Using a stage-wise approach with k-row lookahead could result in a more optimal page than greedy selection, but it comes with increased computational cost. Other approaches to greedily add diversity based on submodular function maximization can also be used.
Even the stage-wise algorithm is not guaranteed to produce an optimal page because a fixed horizon may limit the ability to fill in better rows further down the page. We can take page-wise approach by defining full page scoring function by optimizing rows and videos to fill the page. Since a page layout is defined in a discrete space, directly optimizing a function that defines the quality of the whole page is a computationally prohibitive integer programming problem.
Machine Learning for page generation
At the core of building a personalized page is a scoring function that can evaluate the quality of a row or a page. To include different aspects and adding new data sources, they used ML approach to create the scoring function by training it using historical information of which homepages we have created for our members, what they actually see, how they interact and what they play.
There can be large set of features to represent a row for learning algorithms. We can use any feature like the metadata or index by the position. We can look at past interactions with the row to see if that row or similar such rows have been consumed in the past by the member. Diversity can also be incorporated when considering features of a row compared to the rest of the page by looking at how similar the row is to the rest of the rows or the videos in the row. There can be position biases introduced, so training data should be carefully chosen. Learning over features to represent diversity can also be challenging because while the space of potential rows at different positions on the page is large
Page-level Metrics
Choosing good metrics is important to deal with above challenges. Online can be tested using A/B testing. But to tune the parameters before going online, we need good metrics to test offline.
consider a simple metric like Recall@n, which measures the number of relevant items in the top n divided by the total number of relevant items. We can extend it in two dimensions to be Recall@m-by-n, where now we count the number of relevant items in first m rows and n columns on the page divided by the total number of relevant items. Thus, Recall@3-by-4 may represent quality of videos displayed in the viewport on a device that initially can show 3 rows and 4 videos at a time. One nice property of recall defined this way is that it automatically can handle corner-cases like duplicate videos or short rows. We can also hold one of the values n (or m) fixed and sweep across the other to calculate, for instance, how the recall increases in the viewport as the member would scroll down the page.
Recall is basic metrics and other metrics can be that assign a score or likelihood member seeing position like NDCG or MRR to 2-D case. They also tried adapting models like Expected reciprocal rank to incorporate 2-D navigation through the page and take into account the cascading aspect of browsing.
The above described recommender system design was based on articles in 2018. There has been significant improvement in the recommender system from here where machine learning was advanced to deep learning and reinforcement learning is taking the lead.
Reinforcement Learning for Budget Constrained Recommendations
Netflix has used the Reinforcement Learning (RL) for a scenario where the construction of optimal list of recommendations should be under user finite time budget to make decisions from the list of recommendations. There might be some users who has limited time to search and if the list of recommendations interest them they would have a click otherwise they might exit after looking at few recommendations.
This evaluation process incurs a cost that can be measured in units of time. Different shows will require different amounts of evaluation time. If it’s a popular show like Stranger Things then the user may already be aware of it and may incur very little cost before choosing to play it. Given the limited time budget, the recommendation model should construct a slate of recommendations by considering both the relevance of the items to the user and their evaluation cost. Balancing both of these aspects can be difficult as a highly relevant item may have a much higher evaluation cost and it may not fit within the user’s time budget. The goal for the recommendation algorithm therefore is to construct slates that have a higher chance of engagement from the user with a finite time budget.
Many recommender system rely on bandit style approach to slate construction. If we have to choose k items in the slate, the item scorer scores all of the available N items and make use of slate constructed so far as additional context. The scores are then passed through sampler to select an item from the available items. The item scorer and the sampling step are the main components of the recommender system.

To choose the slate of items, we first model the budget constrained recommendation problem as a Markov Decision Process. In a Markov decision process, the key component is the state evolution of the environment as a function of the current state and the action taken by the agent. In the MDP formulation of this problem, the agent is the recommender system and the environment is the user interacting with the recommender system. The agent constructs a slate of K items by repeatedly selecting actions it deems appropriate at each slot in the slate. The state of the environment/user is characterized by the available time budget and the items examined in the slate at a particular step in the slate browsing process.
The slate generation task above is an episodic task i-e the recommender agent is tasked with choosing K items in the slate. The user provides feedback by choosing one or zero items from the slate. This can be viewed as a binary reward r per item in the slate. Let π be the recommender policy generating the slate and γ be the reward discount factor, we can then define the discounted return for each state, action pair as,
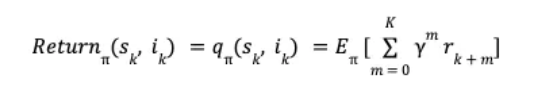
The reinforcement learning algorithm we employ is based on estimating this return using a model. Specifically, we use Temporal Difference learning TD(0) to estimate the value function. Temporal difference learning uses Bellman’s equation to define the value function of current state and action in terms of value function of future state and action
Netflix employs reinforcement learning algorithms to learn the optimal policy — i.e., what item to pick next, given the current state (time left, etc.).
SARSA (on-policy): Learns via simulating actions guided by the same policy being improved. It produced better play rates compared to contextual bandits, especially for users with small to medium budgets
Q-learning (off-policy): Learns optimal value functions from data generated by possibly different policies. Q-learning generated larger effective slate sizes, albeit with similar play rate — suggesting different trade-offs in how full the recommendation slate ends up being
Simulation is central — Netflix can compare different approaches in a controlled environment.
They use:
- Play rate: The average number of items a user actually plays.
- Effective slate size: How many items in the recommended list were actually evaluated (not necessarily played).
- These help them understand trade-offs: maximizing engagement versus giving the user enough options to look at
A recommender system has to balance both the relevance and cost of items so that more of the slate fits within the user’s time budget. It is also proven that the RL outperforms contextual bandits in this problem setting.
Collaborative Retrieval for Large Language Model-based Conversational Recommender Systems
This was the recent paper published in a conference where CRAG (Collaborative Retrieval Augmented Generation) integrates LLMs with collaborative filtering (CF) to improve recommended items through back-and-forth dialogues
LLM usually are good at conversations and generating text in natural language but it does not have context of user-item interactions which is the key for personalized recommendations. This paper aims at combining the context awareness of LLMs with the behavioral patterns captured by CF
This framework has 3 main modules
- LLM based Entity Linking — extracts entities or mentions from dialogue and links to structured item catalog and uses LLM to analyze item and relevance to indicate context relevance.
- Collaborative Retrieval with Context-Aware Reflection — based on extracted item and past interactions in the history, CRAG retrieves relevant candidate items
- Reflect and Re-Rank — After retrieval, the LLM assigns a score to each candidate item, creating a context-aware ranking.
If the user has not mentioned any items, CRAG prompt the LLM to infer likely preferences, extract inferred items via the same entity linking mechanism then proceeds to other steps.
This was evaluated using 2 conversational movie recommendation datasets Reddit-v2 and Redial
The key insights includes:
- Naive CF retrieval alone hurts performance — because irrelevant items dilute the LLM’s decision-making
- Context-aware reflection helps coverage but not ranking
- The final step of reflect and rerank ensures the best items are on the top of the recommendation list
- Asking LLM to look into its own zero-shot generations do not improve results but externally retrieved information is needed
- This is efficient for recent released items because CF data helps surface items outside the LLM’s training cutoff.
As you can see, though recommendation system implemented way back in 2006, there has been significant improvement with the expansion of AI towards reinforcement learning and Generative AI. Let us wait and see where this takes us in future. May be just think and you will have the recommendation system or just show your favorite based on your mood or facial expression.
Happy Learning!!
References:
- https://netflixtechblog.com/netflix-recommendations-beyond-the-5-stars-part-1-55838468f429
- https://netflixtechblog.com/system-architectures-for-personalization-and-recommendation-e081aa94b5d8
- https://netflixtechblog.com/learning-a-personalized-homepage-aa8ec670359a
- https://videorecsys.com/slides/mark_talk3.pdf
- https://netflixtechblog.com/foundation-model-for-personalized-recommendation-1a0bd8e02d39
- https://netflixtechblog.com/fm-intent-predicting-user-session-intent-with-hierarchical-multi-task-learning-94c75e18f4b8
- https://dl.acm.org/doi/10.1145/1498759.1498766
