
A journey from LoRA to Text-to-LoRA — Fine-tuning LLM using prompt
The prompt engineering has become predominant in the world of LLMs and any task can be done in just minutes with less resources and using basic techniques. There was one interesting paper published on June 2025 that caught my eye which Text-To-LoRA, where the most compute intensive and data intensive technique to fine-tune a model can be done using a prompt? Are you kidding? Yes it’s true.
For those who are new to LoRA, Let me explain the LoRA in simple lines and then take you to implementation of a simple task which involves some steps that are compute intensive though I have simplified as much to run on Google Colab, this will definitely give you idea of what LoRA technique is and what is its importance.
Traditional LoRA
Large Language Models are huge. For Example, GPT-3 with 175 billion parameters and Llama-2–7B has 7 billion parameters. Even small models have hundreds of millions of weights. If you fine-tune a model which is adapting the model to a new task, we might have to spend huge GPU memory which is slow training and separate full model copy per task and not scalable in practice.
How can we adapt a large model to a new task by training only a tiny number of parameters while freezing the original model? This question is answered by LoRA which is Low Rank Adaption by exploiting low rank structure.
Most task-specific adaptions do not need full-rank weight updates by weight updates during fine-tuning lie in a low dimensional subspace. So instead of learning a full matrix ΔW, we learn a low rank approximation. This is the idea behind LoRA

This is the original linear layer and with Standard fine — tuning we learn

ΔW is the full rank and requires learning d_out and d_in parameters.
Instead of learning ΔW directly
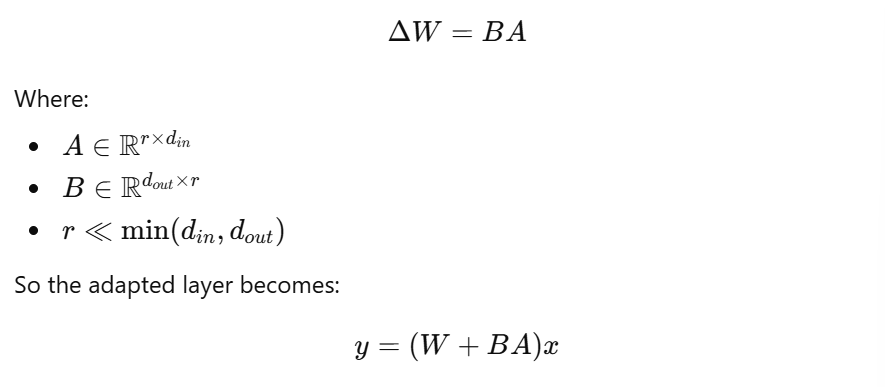
For Example, GPT-2 d_in = d_out = 768. If we have to do full fine tuning we have to train 768 x 768 = 589,894 but with LoRA (r = 8) we have to train 8 x 768 + 768 x 8 = 12,288 which is 48 times less parameters
In LoRA, we freeze the original model weights W and trainable are A and B matrices where A is initialized randomly and B is initialized to zero so initially BA = 0 which means the model behaves like the base model at start.
LoRA is applied to transformers
LoRA is typically applied to attention layers because that is where adaption matters most. Our common targets are Query Projects (Wq), Key Projection (Wk), Value projection (Wv) and Output Projection (Wo)
During backpropagation, Gradients flow only into A and B, W receives no gradients and Optimizer updates only LoRA parameters. So LoRA is memory efficient and allows high batch sizes and train fast.
After training you save only A and B usually a few MB. At inference, load the model, inject LoRA matrices and combine on the fly. This enables Multiple LoRAs per base model, Hot swapping behaviors and mixing adapters
LoRA introduces a scaling factor
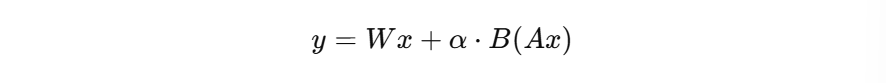
where α controls adaptation strength and often α=r. This ensures stable gradients, comparable update magnitude across ranks.
Limitations
- LoRA is task specific and one LoRA per task/persona.
- It is not dynamic and cannot adapt on the fly without retraining
- It cannot exceed base model’s capacity
Text-To-LoRA
With Classic LoRA, we need a dataset, run fine-tuning and store a LoRA adapter and you repeat this for every task, persona or domain. This causes explosion of LoRA files, slow iteration. high engineering cost and no instant customization
Text-to-LoRA trains a separate model (a hypernetwork) that maps natural-language descriptions directly into LoRA adapter weights.
The architecture involves:
- The base model that never changes, never learns and just runs inference.
- Text Encoder that converts text description into a dense vector
- Hypernetwork that generate LoRA weights A and B
Text-To-LoRA generates A and B directly, no gradient descent at inference and one forward pass through the hypernetwork. The hypernetwork must respect layer-specific shapes. It is also trained to minimize the loss

The hypernetwork distills thousands of LoRA fine-tuning into one generator model.
When we type the description, the text encoder embeds the description and hypernetwork generates LoRA weights A and B matrices for all target layers. LoRA weights are injected into the frozen base LLM. The LLM runs inference normally.
I did create a Text-To-LoRA like with a dummy hypernetwork.
The Difference of Classic LoRA and Text-to-LoRA implementation can be found in the notebook — https://github.com/shilpathota/AI_ML/blob/master/Text_To_LoRA.ipynb
Text-to-LoRA introduces a hypernetwork-based framework that maps natural-language descriptions to LoRA adapter parameters, enabling zero-shot, on-demand adaptation of large language models without gradient-based fine-tuning. By distilling many trained LoRA adapters into a single weight-generating model, the approach significantly reduces customization cost while maintaining strong task performance and controllability.
