
Perceptron — The brain behind Machine Learning
Let us understand the story by moving step by step.
Perceptron for Linear Regression Model
In linear regression, our goal is to find the best fit line with the minimum Mean Square Error.
Mean Square Error — The distance from the datapoint to the point the best fit line be it negative or positive. This is considered as error. To avoid the error being summed up to zero, the distance of each point is squared and then summed. This gives the overall error rate of a best fit line. The best fit line would be the line with Least Mean Squared Error.
What is the Prediction Function?
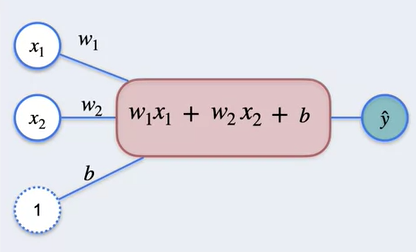
Predicting the output value of y given the inputs x₁, x₂ which are independent variables. The weights for each of the value to predict y is w₁, w₂. Given the bias would be b then the output is
y^ = w₁x₁ + w₂x₂ + b
This is called prediction function. The expression is called the summation function
Loss function would be the Square of difference of actual vs predicted divided by 2.
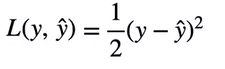
The Gradient Descent main goal would be minimizing the value of Loss function by predicting best values of w₁ , w₂ and b by taking small steps towards minimum value and the step size of learning rate.

How to find values of partial derivatives of w₁ , w₂ and b? For this we can use chain rule.
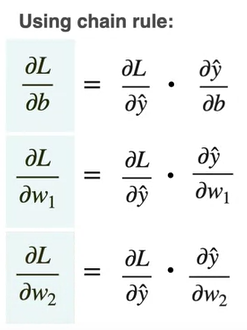
In the above chain rule, we should find the partial derivative of L with respect to y^ and partial derivative of y^ with respect to w₁ , w₂ and b

So from the above calculations, now that we know the partial derivatives.
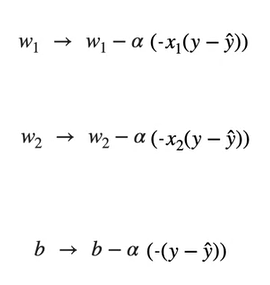
These are the values of w₁ , w₂ and b where α is the learning rate at which gradient descent takes steps.
This is how Perceptron is used in Linear regression problem. Now let us look at Perceptron for binary classification problem.
Perceptron for Binary Classification Problem
For binary classification, we are going to do the same thing like the above for linear regression but additionally we have a sigmoid function which predicts if the output is 0 or 1. This is called activation function.

How does Sigmoid function predict 0 or 1?
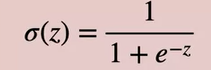

In Machine learning, sigmoid function is very important as the very large value of 1000 is somewhere close to 1 and very small value of -1000 is close to -1. This is very useful in predicting.
What would be the derivative of Sigmoid function?
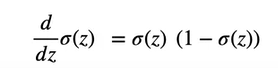

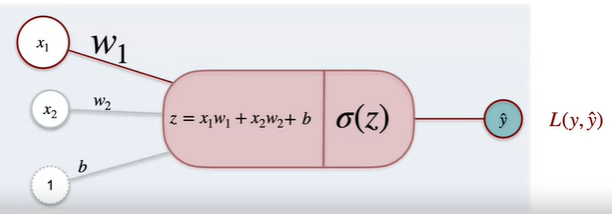
So the sigmoid function is basically applied to the summation function after performing the summation with weights and applying the bias. In this way the output will be either close to 1 or close 0 which is binomial.
The output from sigmoid function would be y^ and the error can be calculated from the actual value and the weights with bias can be adjusted such that the error is minimum
In order for this calculation to work and estimate the best values of weights and bias, For classification we use log loss which is represented with L
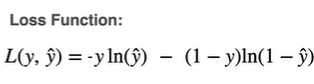
To find the optimal values of w₁ , w₂ and b, we need gradient descent which is calculated with the formula
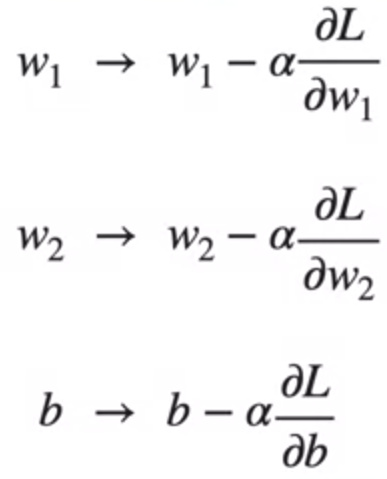
L is the loss function and α is the learning rate at which gradient descent takes steps. First we provide initial values and update the steps based on learning rate
Let us consider w₁, In this case we should calculate how much L is affected with w₁ so that we know how loss function is moving with increase or decrease in w₁. So the partial derivative of L with respect to y^ and partial derivative of y^ with respect to w₁ can give this values using the chain rule.

Similarly for w₂ and b.
Let us first calculate partial derivative of L with respect to y^ which is used for all the three cases.
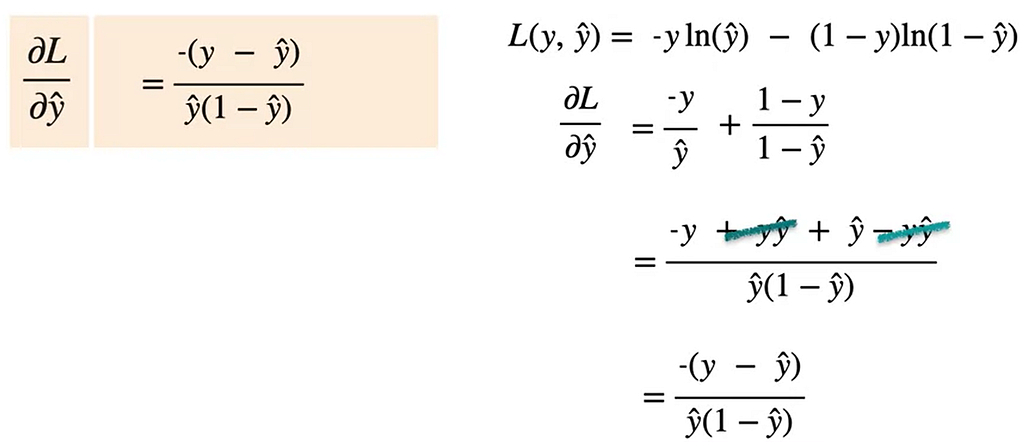
So the values of partial derivatives of w₁ , w₂ and b would be
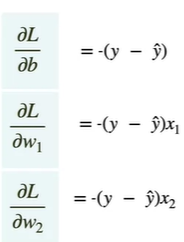
Updating these in the gradient descent we get
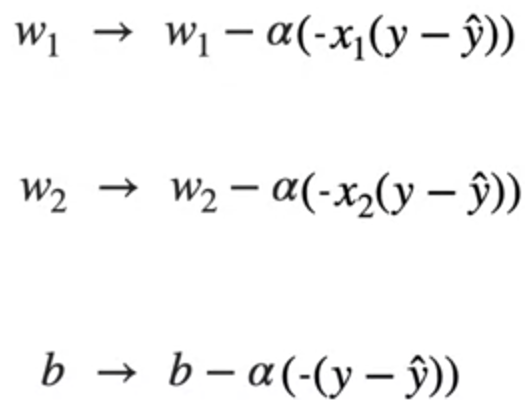
From these formulas we can calculate the gradient descent by increasing steps with learning rate from the initial values. We get the optimal values of w₁ , w₂ and b.
This is the basic level of Perceptron and the first step for neural networks.
References: DeepLearning.AI
