
Understanding architecture, training, reinforcement learning, inference efficiency, and why this paper matters for real-world AI systems.
Over the past two years, Large Language Models (LLMs) have demonstrated remarkable abilities in reasoning, mathematics, coding, and scientific problem-solving. However, these gains have come at a steep computational cost. Many modern reasoning-focused models rely on:
- Massive parameter counts
- Extremely long chain-of-thought outputs
- Slow inference and high memory usage
As a result, deploying reasoning-capable LLMs in production systems — where latency, throughput, and cost matter — is often impractical.
The paper “Llama-Nemotron: Efficient Reasoning Models” (arXiv:2505.00949) directly addresses this gap. Instead of asking “How big can we make the model?”, the authors ask a more practical question:
How do we build reasoning-capable language models that are fast, efficient, and deployable at scale — without sacrificing accuracy?
2. Core Thesis of Llama-Nemotron
The central claim of the paper is:
High-quality reasoning does not require maximal model size — it requires architectural efficiency, disciplined training, and controlled inference behavior.
Llama-Nemotron proposes a family of optimized LLMs that achieve competitive reasoning performance while significantly improving throughput, memory efficiency, and controllability.
This makes the work especially relevant for:
- Enterprise AI platforms
- Edge + cloud hybrid deployments
- AI infrastructure engineers
- Cost-sensitive inference environments
3. Model Family Overview
The authors introduce three primary model variants:
ModelParametersIntended UseNemotron-Nano~8BLightweight reasoning, edge/cloud hybridNemotron-Super~49BBalanced enterprise inferenceNemotron-Ultra~253BState-of-the-art reasoning at scale
Rather than optimizing only the largest model, the paper emphasizes consistent reasoning improvements across all sizes, which is critical for real deployment scenarios.
4. Architectural Optimization: More Than Just Scaling
Unlike many LLM papers that treat architecture as fixed, Llama-Nemotron performs architecture-level optimization.
4.1 Neural Architecture Search (NAS)
The authors apply Neural Architecture Search (NAS) techniques to the base Llama architecture to:
- Reduce redundant computation paths
- Improve attention efficiency
- Optimize layer configurations for inference speed
This results in models that:
- Maintain representational power
- Require fewer FLOPs per token
- Scale more gracefully under load
Crucially, these changes are transparent to downstream users — the model behaves like a standard LLM, but runs faster.
5. The Reasoning Toggle: A Key Innovation
One of the most practically important contributions of the paper is the reasoning mode toggle.
5.1 The Problem with Always-On Reasoning
Many modern LLMs implicitly perform reasoning for every query. This causes:
- Excessively long responses
- Higher latency
- Increased token usage
- Wasted compute for simple queries
5.2 Nemotron’s Solution
Llama-Nemotron introduces conditional reasoning activation:
Standard Mode
- Short, direct responses
- Minimal chain-of-thought
- Optimized for speed
Reasoning Mode
- Step-by-step logical decomposition
- Used only when needed
- Explicitly controlled at inference time
This allows one model to serve:
- Chat applications
- Reasoning-heavy workflows
- Mixed-latency systems without model switching.
6. Training Pipeline: From Base Model to Reasoning Specialist
The training strategy is multi-stage and highly structured.
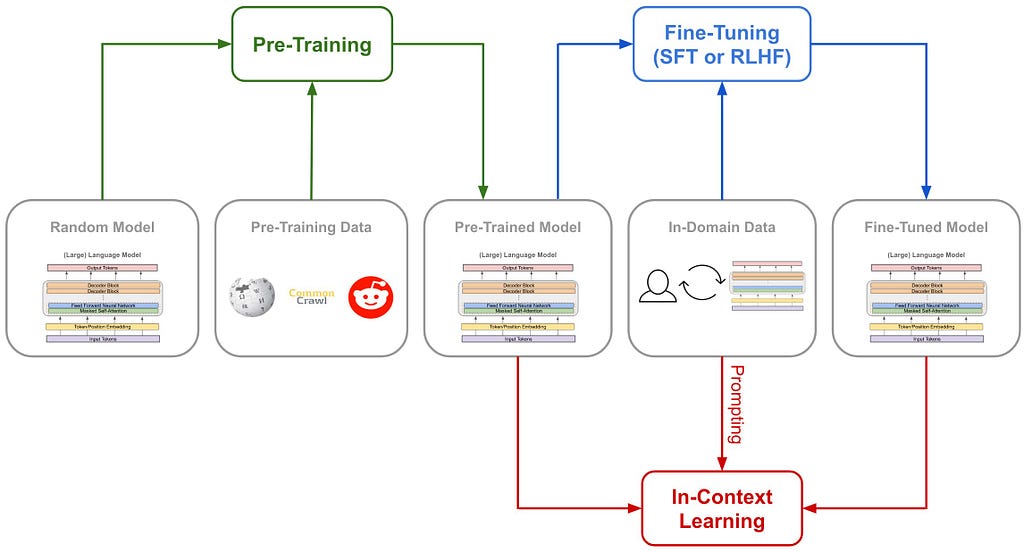
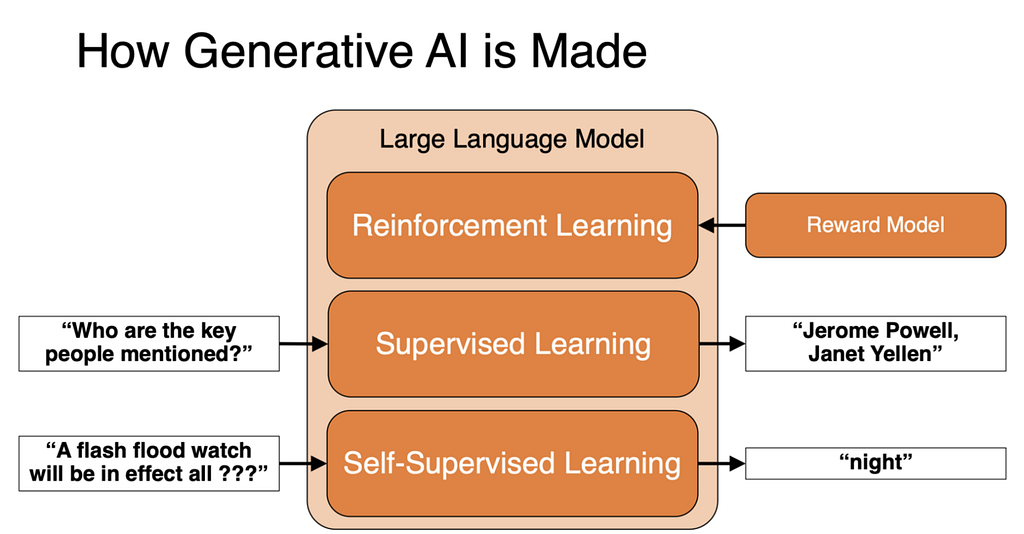
6.1 Stage 1 — Foundation Pretraining
The Nemotron models start from a Llama-based foundation pretrained on large-scale text corpora, ensuring strong language understanding and generalization.
6.2 Stage 2 — Knowledge Distillation
To avoid losing performance due to architectural changes, the models undergo knowledge distillation, where:
- Outputs from stronger teacher models
- Guide the learning of Nemotron variants
- Preserve reasoning patterns and linguistic nuance
This stage ensures that efficiency gains do not degrade intelligence.
6.3 Stage 3 — Supervised Fine-Tuning (SFT)
The authors curate reasoning-focused datasets, including:
- Mathematical problem solving
- Code reasoning and debugging
- Scientific explanations
- Multi-step logical inference
SFT teaches the model:
- When to reason
- How to structure intermediate steps
- How to reach verifiable conclusions
6.4 Stage 4 — Reinforcement Learning (RL)
This is where Nemotron distinguishes itself.
Instead of optimizing for verbosity, the RL phase rewards:
- Correctness of final answer
- Logical consistency
- Minimal yet sufficient reasoning
This discourages:
- Hallucinated reasoning
- Over-long explanations
- Spurious intermediate steps
The result is high signal-to-noise reasoning.
6.5 Stage 5 — Alignment and Safety Tuning
A final alignment phase ensures:
- Instruction adherence
- Stable conversational behavior
- Safe deployment in production
7. Benchmark Performance and Efficiency
The paper evaluates Nemotron across standard reasoning benchmarks (math, logic, coding).
Key Observations
- Nemotron-Ultra matches or exceeds larger reasoning models
- Nemotron-Super often delivers better accuracy-per-compute
- Inference throughput is consistently higher than comparable models
This confirms the paper’s core thesis:
Efficiency and reasoning quality are not mutually exclusive.
8. Why This Paper Matters (Beyond Benchmarks)
8.1 Production-First Thinking
Unlike many academic LLM papers, Nemotron is designed with:
- GPU memory limits
- Inference cost
- Latency SLAs in mind.
8.2 Implications for AI Infrastructure
For AI infra engineers, this paper highlights:
- The importance of architecture-aware model design
- Conditional reasoning as a cost-control mechanism
- RL as a tool for behavior shaping, not just performance gains
8.3 A Shift in LLM Research Direction
Llama-Nemotron signals a broader shift:
- From “bigger is better”
- To “smarter, cheaper, and controllable”
This aligns with emerging needs in:
- Enterprise AI
- Edge inference
- Hybrid cloud systems
9. Limitations and Open Questions
The authors are transparent about trade-offs:
- Ultra-scale models still require massive hardware
- Reasoning toggles require careful prompt design
- Long-term generalization remains an open challenge
These are engineering problems — not conceptual flaws.
10. Final Takeaway
Llama-Nemotron is not just another LLM release.
It is a systems-oriented rethink of reasoning models.
The future of LLMs will not be defined by size alone — but by efficiency, control, and deployability.
For anyone building real-world AI systems, this paper is essential reading.
