
Evaluating ML models is difficult and with introduction of foundation models it is even more difficult. The more intelligent AI models become, the harder is to evaluate them. With the traditional approach it is open ended nature of foundation models.
Publicly available evaluation benchmarks have proven to be inadequate for evaluating foundation models. A benchmark becomes saturated for a model once the model achieves the perfect score. With foundation models, benchmarks becomes saturated fast. The scope of evaluation has expanded for general purpose models. With task specific models, evaluation involves measuring a model’s performance on its trained task.
There are new challenges of evaluation have prompted many new methods and benchmarks. with this, there is inadequate investment leading to inadequate infrastructure, making it hard for people to carry out systematic evaluations.
Language Modeling Metrics
The metrics used to guide the development of language models haven’t changed from 1951. Most autoregressive language models are trained using cross entropy or its relative perplexity. We also have bits-per-character(BPC) and bits-per-byte (BPB) both are variations of cross entropy
Entropy
Entropy measures how much information on average a token carries. The higher the entropy the more information each token carries and the more bits are needed to represent a token.
Entropy measures how difficult it is to predict what comes next in a language. The lower a language’s entropy, the more predictable that language.
Cross Entropy
When you train a language model on a dataset your goal is to get the model to learn the distribution of this training data. The goal is to get the model to predict what comes next in the training data. A language model’s cross entropy on a dataset measures how difficult it is for the language model to predict what comes next in this dataset.
A model’s cross entropy on the training data depends on two qualities
- The training data’s predictability measured by the training data’s entropy
- How distribution captured by the language model diverges from the true distribution of the training data
Bits-per-Character and Bits-per-Byte
One unit of entropy and cross entropy is bits. If the cross entropy of a language model is 6 bits, this language model needs 6 bits to represent each token.
Since different models have different tokenization methods — for example, one model uses words as tokens and another uses characters as tokens — the number of bits per token isn’t comparable across models. Some use the number of bits-per-character (BPC) instead. If the number of bits per token is 6 and on average, each token consists of 2 characters, the BPC is 6/2 = 3.
Cross entropy tells us how efficient a language model will be at compressing text. If the BPB of a language model is 3.43, meaning it can represent each original byte (8 bits) using 3.43 bits, this language model can compress the original training text to less than half the text’s original size.
Perplexity
Perplexity is the exponential of entropy and cross entropy. Perplexity is often shortened to PPL. Given a dataset with the true distribution P, its perplexity is defined as:
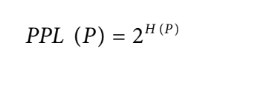
If cross entropy measures how difficult it is for a model to predict the next token, perplexity measures the amount of uncertainty it has when predicting the next token. Higher uncertainty means there are more possible options for the next token.
Popular ML frameworks, including TensorFlow and PyTorch, use nat (natural log) as the unit for entropy and cross entropy. Nat uses the base of e, the base of natural logarithm. If you use nat as the unit, perplexity is the exponential of e:
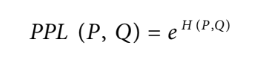
Due to the confusion around bit and nat, many people report perplexity, instead of cross entropy, when reporting their language models’ performance.
Cross entropy, perplexity, BPC, and BPB are variations of language models’ predictive accuracy measurements.
Perplexity is excellent for:
- GPT-style model A vs model B
- Base model vs fine-tuned model
- Model version tracking over time
Very useful for:
- Domain-specific models (medical, legal, code)
- Checking if fine-tuning actually helped
High perplexity on training/validation data may indicate:
- Noisy text
- Corrupted samples
- Mismatch between tokenizer and language
Perplexity is best used
- Before product-level evaluation
- During model training iterations
Exact Evaluation
Exact Evaluation refers to evaluation methods in which an AI system’s output can be objectively and deterministically verified against a known ground truth, without ambiguity or human judgment. This type of evaluation is possible when tasks have a single correct answer or a strictly defined set of valid outputs — such as arithmetic problems, code execution, structured data extraction, SQL query results, or schema-validated JSON generation. In these cases, evaluation can be fully automated using techniques like string matching, numerical comparison, program execution, unit tests, or rule-based validators, making it highly reliable, reproducible, and scalable. As emphasized in AI Engineering by Chip Huyen, exact evaluation is especially valuable because it removes subjectivity and evaluator bias, enabling fast iteration and regression testing; however, its applicability is limited, since most real-world generative AI tasks (summarization, reasoning, open-ended QA, creative writing) do not have a single “correct” answer and therefore require approximate, functional, or human-in-the-loop evaluation methods instead.
Functional Correctness
Functional Correctness is an evaluation approach that measures whether an AI system’s output successfully performs the intended function, even if the exact wording or structure differs from a reference answer. Instead of checking for exact matches, this method validates outputs by executing, simulating, or applying them in a real or test environment to see if they achieve the desired outcome — for example, running generated code to confirm it compiles and passes unit tests, executing an SQL query to verify it returns the correct results, or applying an API call to ensure it produces the expected side effects.
Similarity Measurements Against Reference Data
Similarity Measurements Against Reference Data evaluate AI-generated outputs by comparing them to one or more high-quality reference answers using quantitative similarity metrics rather than exact matching. This evaluation approach acknowledges that many generative tasks — such as summarization, translation, paraphrasing, and question answering — can have multiple valid outputs, making exact evaluation impractical. In this method, the model’s output is measured against reference data using lexical metrics (such as BLEU, ROUGE, or METEOR), semantic similarity scores based on embeddings (cosine similarity in vector space), or learned similarity models that estimate meaning overlap. The section explains that lexical metrics work well when surface-level overlap matters (e.g., translation benchmarks), but they often fail to capture meaning when phrasing differs significantly; embedding-based similarity is therefore preferred for modern LLM evaluation because it captures semantic equivalence even when wording changes. However, similarity-based evaluation still has limitations: it depends heavily on the quality and coverage of reference data, can penalize creative or novel but correct answers, and may reward outputs that are semantically close yet factually incorrect. As a result, similarity measurements are best used as approximate, scalable signals in evaluation pipelines, often combined with functional tests or human/AI judgment rather than used as a sole measure of quality.
Embeddings
An Embedding is a numerical representation that aims to capture the meaning of the original data. It is a vector. Models trained especially to produce embeddings include the open source models BERT, CLIP and Sentence Transformers.
Because models typically require their inputs to first be transformed into vector representations, many ML models, including GPTs and Llamas, also involve a step to generate embeddings.
The goal of the embedding algorithm is to produce embeddings that capture the essence of the original data. level, an embedding algorithm is considered good if more-similar texts have closer embeddings, measured by cosine similarity or related metrics. You can also evaluate the quality of embeddings based on their utility for your task. Embeddings are used in many tasks, including classification, topic modeling, recommender systems, and RAG.
A joint embedding space that can represent data of different modalities is a multimodal embedding space. In a text–image joint embedding space, the embedding of an image of a man fishing should be closer to the embedding of the text “a fisherman” than the embedding of the text “fashion show”. This joint embedding space allows embeddings of different modalities to be compared and combined.
AI as a Judge
AI as a Judge is an evaluation approach in which a capable language model is used to assess the quality of another model’s output by following a structured rubric or comparison criteria. Instead of relying on exact matches or similarity scores, the judge model evaluates aspects such as correctness, relevance, reasoning quality, completeness, safety, and instruction adherence, making it particularly useful for open-ended generative tasks where no single ground-truth answer exists. The section explains that this method scales far better than human evaluation and often correlates well with expert judgment when the evaluation prompt is carefully designed, the criteria are explicit, and the judge model is sufficiently strong. However, AI-based judges can inherit biases, be inconsistent, or favor outputs stylistically similar to their own training data, so their judgments should be validated with spot-checked human reviews and combined with other evaluation signals rather than treated as an absolute authority.
Future of Comparative Evaluation
The Future of Comparative Evaluation points toward evaluation methods that focus less on absolute scores and more on relative, head-to-head comparisons between model outputs, because humans and models alike are more consistent at judging which response is better than assigning an independent quality score. The section explains that as AI systems become more capable and tasks more open-ended, ranking outputs side-by-side (pairwise or listwise comparisons) will increasingly replace standalone metrics like accuracy or perplexity, especially for reasoning, writing, and agent behavior. Future comparative evaluation is expected to rely heavily on strong AI judges, standardized rubrics, and large-scale preference data, enabling faster iteration and more nuanced quality signals. However, it also highlights open challenges: scaling comparisons without bias, preventing judge-model self-preference, handling non-transitive rankings, and ensuring alignment between comparative scores and real user satisfaction. As a result, comparative evaluation is likely to evolve into a hybrid system — combining AI judges, selective human audits, and task-specific signals — serving as a core pillar of evaluation pipelines for production-grade AI systems rather than a standalone solution
Summary
This chapter explains why evaluation is one of the hardest and most critical problems in AI engineering, especially for foundation models whose outputs are probabilistic, open-ended, and often lack a single correct answer. It begins by highlighting the limitations of traditional ML metrics when applied to generative models and introduces language-model–specific metrics such as entropy, cross-entropy, and perplexity, clarifying that these measure language fluency rather than task success. The chapter then categorizes evaluation methods into exact evaluation (objective, deterministic checks), functional correctness (verifying behavior through execution or outcomes), and similarity measurements against reference data (lexical and semantic comparison using metrics and embeddings). Recognizing that many real-world tasks cannot be reliably evaluated with these methods alone, the chapter introduces AI as a Judge, where strong models evaluate outputs using structured rubrics, and comparative evaluation, which ranks outputs relative to one another instead of assigning absolute scores. It concludes by emphasizing that no single metric is sufficient: robust AI systems require multi-signal evaluation pipelines combining automated checks, AI judges, and selective human review to balance scalability, reliability, and real-world usefulness.
References
- Shannon, C. E. Prediction and Entropy of Printed English, 1951 — foundational work behind entropy and language modeling.
- Devlin, J. et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 2018 — masked language modeling and evaluation context.
- Vaswani, A. et al. Attention Is All You Need, 2017 — transformer architecture underlying modern LLMs.
- Papineni, K. et al. BLEU: A Method for Automatic Evaluation of Machine Translation, 2002 — lexical similarity evaluation.
- Lin, C.-Y. ROUGE: A Package for Automatic Evaluation of Summaries, 2004 — reference-based similarity evaluation.
- Reimers, N., & Gurevych, I. Sentence-BERT, 2019 — embedding-based semantic similarity.
