
This article is about the research paper in the link. This research introduces a new method — called SynergyRCA — to find the root cause of failures in Kubernetes (a system for running and managing software across many computers). Root cause analysis (RCA) means figuring out exactly why something failed. SynergyRCA uses Large Language Models (LLMs) like GPT-4o together with structured data stored in graphs to analyze incidents more effectively and accurately.
Kubernetes is widely used in cloud computing to run services reliably. But it’s complex — made up of many interconnected parts that constantly update and interact. When something goes wrong (e.g., a service stops working), it’s difficult and time-consuming to find the actual cause.
Traditional tools either:
- rely on rule books that are hard to maintain, or
- use LLMs alone without structured context, which can make mistakes (hallucinate or fail to capture real system behavior).
SynergyRCA aims to fix that by combining LLMs with database graphs that represent real runtime behavior.
What is a graph and why use it?
The authors create two types of graphs
StateGraph
- Shows how every entity in the Kubernetes cluster is connected at different points in time.
- Imagine a map showing all running services, their current states, and how they depend on each other.

MetaGraph
- A summary map that shows the general relationships among types of entities (like “Pods”, “Jobs”, “ConfigMaps”).
- It gives the LLM a bird’s-eye view of possible dependencies.

These two together let the system query and retrieve relevant context before asking the LLM for help.
How SynergyRCA works (step-by-step)
When a failure occurs:
👣 Step 1 — Incident arrives
A failure message (e.g., error logs) enters the system.
👣 Step 2 — Triage (LLM looks at initial info)
The LLM first guesses the most likely problematic resource based on the message. Think of it like an expert making a first guess.
👣 Step 3 — Query graph for context
Using this guess, SynergyRCA pulls related data from the StateGraph + MetaGraph — like a detective gathering clues.
👣 Step 4 — Check states
For each related entity found in the graph, the system checks current states (like: Is this service healthy? Is this config missing?).
👣 Step 5 — Report generation
The LLM combines the gathered context with expert prompts (guidance rules from human operators) and produces a clear root-cause explanation and suggested fixes.
👣 Step 6 — Quality check
A final check ensures the explanation makes sense — if not, the system repeats a deeper search.
What makes SynergyRCA special?
✔️ Uses LLMs smartly
Instead of asking the LLM blindly (which can cause mistakes), it provides structured data from graphs and expert tips so answers are more accurate.
✔️ Automatically builds graphs
It extracts runtime relationships from Kubernetes clusters and stores them, no manual tuning needed.
✔️ Works in real clusters
The authors tested it on real production clusters from different environments and versions — not just simulations
How well does it perform?
SynergyRCA was tested using workloads from two Kubernetes clusters:
- Found 18–20 types of root causes in real failure logs.
- Identified five new kinds of problems unseen before in one dataset.
- Took ~2 minutes on average to find root causes.
- Achieved about 90% accuracy in pinpointing correct causes.
This shows the approach isn’t just theoretical — it works practically and reliably.
Core Architecture Overview
At a high level, SynergyRCA consists of four tightly coupled subsystems:
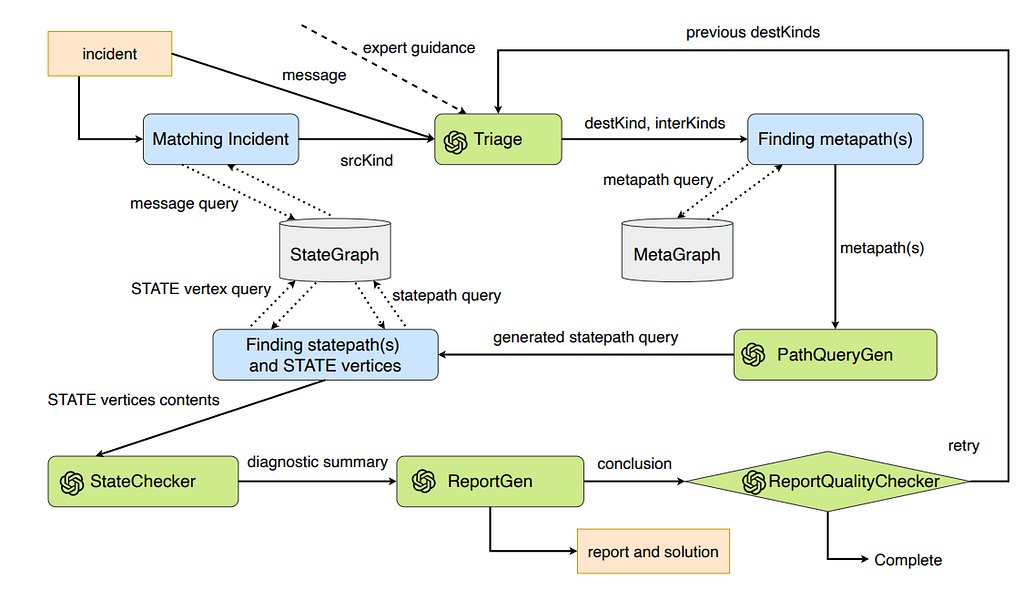
The Triage module is the entry point of the SynergyRCA pipeline. Its sole responsibility is to narrow the RCA search space by predicting where in the Kubernetes system the root cause is most likely located.
Triage does NOT determine the root cause itself.
It predicts candidate locations to guide graph traversal.
Triage in SynergyRCA is a graph-guided LLM reasoning step that transforms an unstructured Kubernetes incident into a constrained root-cause search plan. When an incident occurs, the system first queries the StateGraph to deterministically identify the source resource kind (srcKind) emitting the error, grounding the analysis in observed runtime state. The LLM is then prompted to infer relevant intermediate dependency kinds (interKinds) and the most likely destination kind (destKind) where the root cause resides, using semantic understanding of Kubernetes failures rather than raw pattern matching. To prevent hallucination, the prompt enforces a closed taxonomy of valid Kubernetes entity kinds, incorporates expert heuristics to prioritize common failure domains (e.g., NFS, container images, volumes), and leverages naming conventions to probabilistically infer resource types. The LLM output is strictly constrained to a JSON schema, enabling automated downstream graph traversal. This triage process dramatically reduces the RCA search space while remaining zero-shot, relying on the LLM’s general Kubernetes knowledge combined with graph-based grounding rather than cluster-specific training.
PathQueryGen is an LLM-driven code generation module that converts a validated metapath (derived from the MetaGraph) into an executable Cypher query over the StateGraph, ensuring structurally correct graph traversal for RCA. It augments the metapath by prepending a fixed incident anchor sequence (EVENT → Event → srcKind) so that graph queries are always rooted in the actual failure event, then iteratively generates MATCH–WHERE clauses for each edge in the path (e.g., Event → Pod → PVC → PV → nfs). Each edge is translated using precise relationship types (such as HasEvent, ReferInternal, UseExternal) and constrained by key-based conditions (e.g., spec_claimRef_uid) to preserve semantic correctness. By strictly following the MetaGraph-defined metapath, PathQueryGen prevents the LLM from hallucinating invalid connections (such as non-existent PV → Node → nfs paths) and guarantees that the resulting Cypher query is both executable and faithful to Kubernetes semantics. This approach leverages the LLM’s code synthesis strength while using graph schema constraints as guardrails, making it especially effective for generating flexible, incident-specific statepath queries rather than static graph queries.
StateChecker is the verification module in SynergyRCA that ensures candidate root causes identified through graph traversal are factually valid and causally consistent with the incident before involving the LLM for explanation. After PathQueryGen retrieves statepaths from the StateGraph, StateChecker systematically evaluates each node and relationship along the path by inspecting their runtime states, attributes, and temporal transitions (e.g., creation time, deletion time, error state). It checks whether a resource is in an abnormal or unexpected state (such as a missing ConfigMap, a deleted PVC, or an inaccessible NFS path), and critically verifies causal ordering, ensuring that the suspected cause occurred before the observed failure event. If a candidate fails these checks — such as being healthy, irrelevant, or temporally inconsistent — it is pruned from consideration. By grounding RCA in verified system state rather than probabilistic inference alone, StateChecker acts as an anti-hallucination guardrail that filters false positives and guarantees that only evidence-backed root causes are passed to the final LLM-based explanation stage.
ReportGen is the final synthesis module in SynergyRCA that transforms verified root-cause evidence into a clear, human-readable incident report using an LLM. After StateChecker filters and validates candidate statepaths, ReportGen is provided with only fact-checked graph evidence, including the faulty resource, its abnormal state, the dependency chain, and temporal ordering. Guided by structured prompts and expert instructions, the LLM generates a concise explanation describing what failed, why it failed, how the failure propagated through the system, and actionable remediation steps, while explicitly avoiding unsupported assumptions. Because ReportGen operates strictly on validated StateGraph data rather than raw logs or speculative reasoning, it produces trustworthy, operator-ready RCA reports that balance technical accuracy with readability, enabling SREs and platform engineers to quickly understand and resolve Kubernetes incidents.
ReportQualityChecker is the final validation layer in SynergyRCA that assesses the consistency, completeness, and evidence alignment of the generated RCA report before it is presented to users. After ReportGen produces a natural-language explanation, ReportQualityChecker cross-checks the report against the underlying StateGraph evidence and StateChecker outputs to ensure that every claimed cause, dependency, and remediation step is explicitly supported by verified system states and correct temporal ordering. It flags logical gaps, unsupported assertions, or missing key elements (such as the identified root cause, failure timeline, or corrective action), and if deficiencies are detected, it triggers a feedback loop that prompts additional graph traversal or report regeneration. By enforcing evidence-grounded explanations and quality thresholds, ReportQualityChecker prevents misleading or incomplete RCA narratives and ensures that the final report is reliable, actionable, and suitable for operational decision-making.
Why this is useful for the tech community
- Helps DevOps and SRE teams solve incidents much faster
- Reduces downtime and losses in cloud environments
- Avoids expensive manual debugging or brittle rule systems
- Combines human expertise + AI + structured runtime data efficiently
References
- https://arxiv.org/pdf/2506.02490 — Simplifying Root Cause Analysis in Kubernetes with StateGraph and LLM
