
In today’s world, systems that react to events as they happen — whether it’s a bank transaction, IoT sensor update, or AI model request — are no longer “nice-to-have.” They’re mission-critical. But building event-driven systems that are fast, scalable, cost-effective, and intelligently managed is hard. Traditional benchmarks and decision guides fall short. That’s where a recent research paper, “Next-Generation Event-Driven Architectures: Performance, Scalability, and Intelligent Orchestration Across Messaging Frameworks” (Arafat et al., Oct 2025), provides groundbreaking insights.
In this article, we’ll break down this research in simple, detailed language — fully covering the problem, methodology, discoveries, and practical takeaways. Whether you’re an engineer, architect, or tech leader, you’ll get a clear picture of how next-gen event systems should be built and evaluated.
Why This Research Matters
Event-driven systems power everything from financial platforms processing millions of transactions per second to AI pipelines orchestrating complex, compute-intensive workloads. But:
- Existing benchmarks are inconsistent and unrealistic, often using toy workloads that don’t reflect real operational conditions.
- Framework comparisons have been fragmented, focusing only on isolated performance metrics rather than real use cases.
- Orchestration is usually static or reactive, leaving resources under-utilized and unable to anticipate traffic spikes.
The authors set out to answer four core questions:
- How do different messaging systems perform under realistic workloads?
- Can machine learning improve orchestration beyond static configurations?
- How does the choice of system change based on workload type?
- Can we build practical guidelines for choosing the right system?
The Systems Compared
The study evaluated 12 messaging frameworks, including:
- Traditional brokers: Apache Kafka, RabbitMQ
- Cloud-native streaming: Apache Pulsar, NATS JetStream
- Lightweight streaming: Redis Streams
- Serverless event buses: AWS EventBridge, Google Cloud Pub/Sub, Azure Event Grid, Knative Eventing and several others.
Each embodies a different architectural philosophy, and the goal was to benchmark them fairly under standardized, real-world-like workloads.
Experimental Testbed & Infrastructure Details
The authors designed a controlled yet production-realistic experimental environment rather than relying on synthetic micro-benchmarks. All messaging frameworks were deployed on Kubernetes clusters with uniform hardware constraints to ensure fairness.
Infrastructure details included:
- Multi-node Kubernetes clusters with horizontal pod autoscaling
- Uniform CPU and memory limits across brokers
- Persistent storage enabled where applicable (Kafka, Pulsar)
- Network latency emulation to reflect cross-zone deployments
- Realistic message sizes (1 KB — 1 MB), not fixed toy payloads
Each framework was tested under identical workload injection patterns, removing bias from vendor-specific tuning. This rigor is one of the strongest aspects of the paper and is often missing in prior benchmarking studies.
Realistic Workloads
Instead of synthetic, simplistic tests, the researchers designed three representative workloads:
- E-commerce transactions — demanding exactly-once delivery and high throughput
- IoT telemetry ingestion — huge volume, bursty traffic, and variable message sizes
- AI inference pipelines — dynamic processing time and latency sensitivity
This approach mirrors real systems far better than prior benchmarks.
Detailed Workload Modeling Strategy
Instead of measuring raw throughput alone, the workloads were behavior-driven, meaning they modeled how real systems behave over time.
E-commerce Transaction Stream
- Burst traffic during flash sales
- Strict ordering and delivery guarantees
- Stateful consumer logic
- Back-pressure intentionally introduced
IoT Telemetry Stream
- Millions of small messages per second
- Sudden spikes caused by sensor synchronization
- Variable arrival rates
- Partial message loss tolerance
AI / ML Inference Stream
- Events trigger compute-heavy downstream tasks
- Variable processing latency per message
- Queue buildup impacts end-to-end latency
- Strong sensitivity to orchestration quality
This design ensures the results translate directly to production systems, especially AI pipelines where message latency ≠ processing latency.
Intelligent Orchestration: AIEO
One of the paper’s biggest contributions is AIEO — AI-Enhanced Event Orchestration. Instead of static rules or simple autoscaling, AIEO:
Key Features
- Predictive Scaling — Uses time-series forecasting (e.g., ARIMA, LSTM, Prophet) to anticipate load.
- Reinforcement Learning (RL) — Trains agents (via Proximal Policy Optimization) to dynamically allocate resources for optimal throughput and latency.
- Adaptive Routing — Moves events intelligently based on system state and predicted demand.
- Multi-Objective Optimization — Balances performance, cost, and resource use.
This approach fundamentally shifts orchestration from reactive to proactive, reducing delays and minimizing overprovisioning.
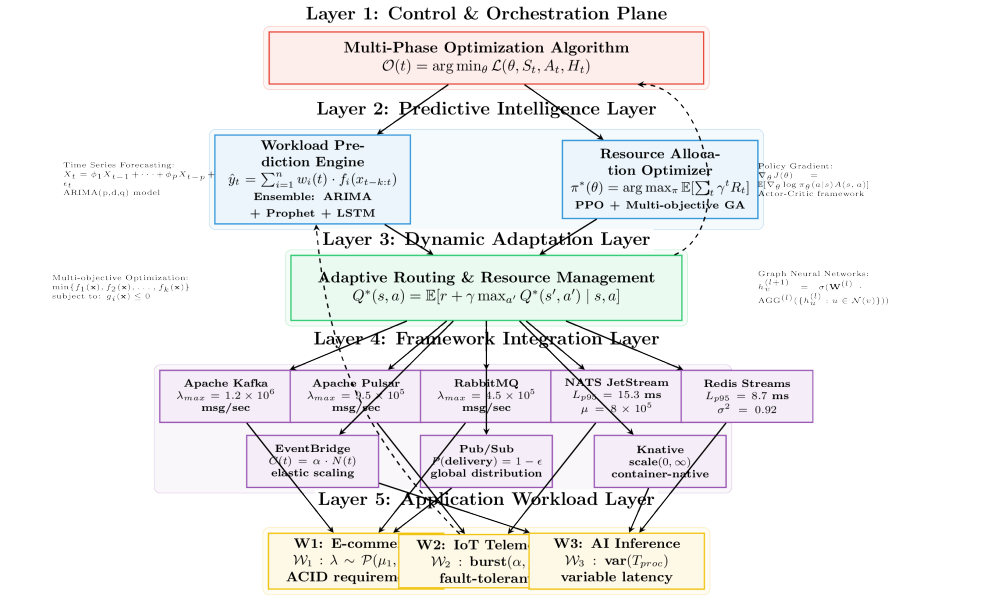
AIEO is not a single algorithm — it is a multi-layer intelligence plane.
Prediction Layer
- Uses time-series forecasting (ARIMA, Prophet, LSTM)
- Predicts incoming message rates minutes ahead
- Anticipates load before brokers saturate
Decision Layer
Implements reinforcement learning agents
- State space includes: Queue depth, Consumer lag, CPU & memory utilization, Network congestion
- Actions include: Scaling brokers, Adjusting partitions, Rerouting event flows
- Reward function balances: Latency Throughput, Cost, Resource stability
Execution Layer
- Applies decisions via Kubernetes APIs
- Integrates with autoscalers and broker configs
- Ensures decisions remain reversible (no catastrophic scaling)
This layered design makes AIEO portable across frameworks, not locked to Kafka or any single broker.
Benchmark Results
Overall Performance
Across the workloads:

Here’s what this means:
- Kafka is undisputed for raw throughput, but requires significant expertise to operate and tune.
- Pulsar provides a balanced mix of performance and manageability.
- Serverless options are elastic and easy, but introduce higher baseline latency and potential vendor lock-in.
Latency Breakdown Analysis
The paper goes beyond average latency and analyzes latency composition:
- Producer → Broker latency
- Broker internal processing delay
- Consumer lag
- Downstream processing wait time
Key finding:
Broker performance alone does not determine system latency — orchestration quality often dominates.
In AI workloads, poorly orchestrated consumers caused queue buildup, multiplying end-to-end latency even when broker throughput remained high.
This insight explains why serverless systems sometimes underperform despite elastic scaling — orchestration latency becomes the bottleneck.
What AIEO Achieves
With the AIEO orchestration layer applied across all systems, the researchers observed:
- 34% average latency reduction
- 28% improvement in resource utilization
- 42% cost optimization
These are major gains — translating into smoother, cheaper, and more predictable operations.
Cost-Performance Trade-off Analysis
The authors introduce a cost-normalized performance metric, comparing:
- Throughput per dollar
- Latency per compute unit
- Idle resource waste
Findings:
- Kafka delivers the best raw performance
- Serverless systems deliver the lowest operational burden
- AIEO significantly narrows the cost gap by:
- Preventing over-scaling
- Reducing idle brokers
- Avoiding reactive scale storms
This makes AI-orchestrated systems economically viable at scale, especially for unpredictable workloads.
Failure & Stress Scenarios
The experiments included failure injection, such as:
- Broker crashes
- Network partitions
- Consumer restarts
- Sudden 10× traffic spikes
With traditional static orchestration:
- Recovery was slow
- Manual intervention was often required
With AIEO:
- Systems recovered faster
- Scaling actions were proactive
- Consumer lag stabilized earlier
This positions AIEO as not just a performance enhancer, but a resilience mechanism.
Trade-Offs and Practical Insights
Kafka
Pros:
- Best throughput and lowest latency
- Strong ecosystem and tooling
Cons:
- High operational overhead
- Harder to scale multi-tenant workloads
Pulsar
Pros:
- Great balance of performance and ease
- Built-in multi-tenancy
Cons:
- Slightly lower peak performance
- Smaller ecosystem
Serverless
Pros:
- Autoscaling built-in
- Low operational needs
Cons:
- Higher latency
- Less control and potential cost unpredictability
Decision Framework and Guidelines
One of the most actionable parts of the paper is a decision matrix and guidelines that help teams choose:
✔ Based on workload
✔ Based on performance requirements
✔ Based on operational expertise
✔ Based on cost constraints
This transforms benchmarking from academic numbers to real architectural advice.
Research Gaps & Open Challenges
The paper also identifies unresolved challenges:
- RL training cost in production
- Cold-start behavior for new workloads
- Explainability of AI decisions
- Risk of cascading orchestration actions
These are future research directions, especially relevant for:
- LLM-driven infrastructure agents
- Autonomous SRE systems
- Self-healing data platforms
Why This Matters for LLM & GenAI Pipelines
Modern LLM systems increasingly rely on:
- Streaming prompts
- Event-driven inference
- Multi-agent coordination
- Feedback loops
This paper provides a foundational blueprint for:
- Agent-to-agent communication via Kafka
- Predictive scaling for inference bursts
- Cost-aware orchestration of LLM services
In effect, it connects event streaming infrastructure with agentic AI systems, a direction that is still under-explored in academic literature.
Final Thoughts
Event-driven systems are at the heart of modern distributed applications. But without realistic evaluation and intelligent management, even the best frameworks can underperform. This research sets a new bar for how we benchmark, orchestrate, and deploy event systems — bringing AI-driven intelligence into distributed architecture.
If you’re designing high-performance, scalable systems — whether for fintech, IoT, or AI — understanding this work will give you a competitive edge.
References
Arafat, J., Tasmin, F., Poudel, S., & Tareq, A. “Next-Generation Event-Driven Architectures: Performance, Scalability, and Intelligent Orchestration Across Messaging Frameworks.” arXiv, Oct 2025.
https://medium.com/media/dc92c26bbc800f6a821011e8dcbb99d7/href